Subly / 2025–2026 / AI Product Design
Designing an AI-Orchestrated Audio Description System
Shipped 2 versions in 8 sprints as sole designer. Designed the full AI pipeline, including all prompt engineering, and led the shift from script-first control to automation-first delivery.
The Challenge
Enterprise deals were stalling on one missing feature.
AI-powered Audio Description was the last piece of Subly's accessibility suite, and enterprise deals were stalling without it. As sole designer and product lead, I owned it end-to-end: problem definition, AI pipeline and prompt architecture, UX, and shipping two complete versions in 8 sprints.
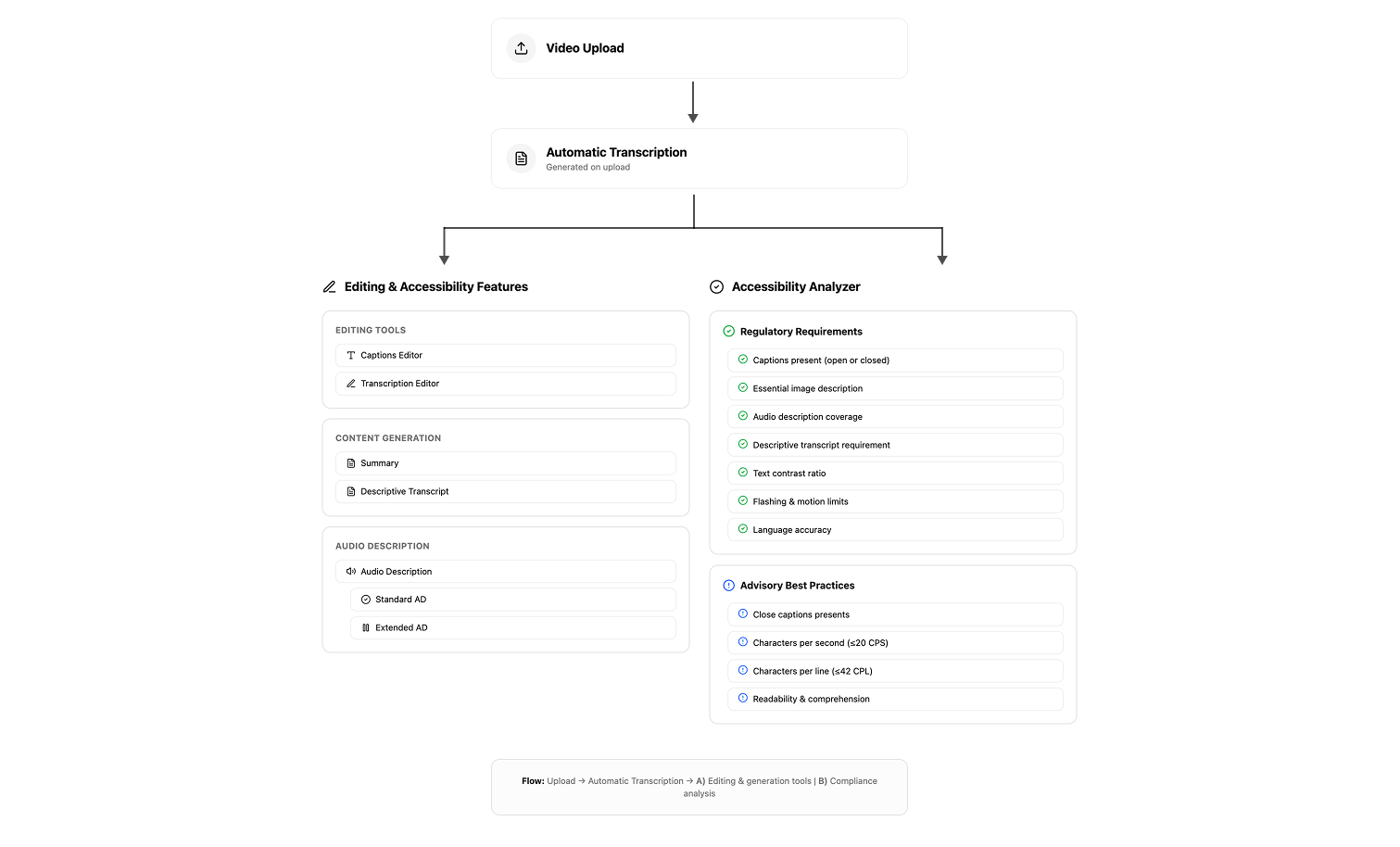
Subly's accessibility suite. Audio Description was the last missing piece for enterprise compliance.
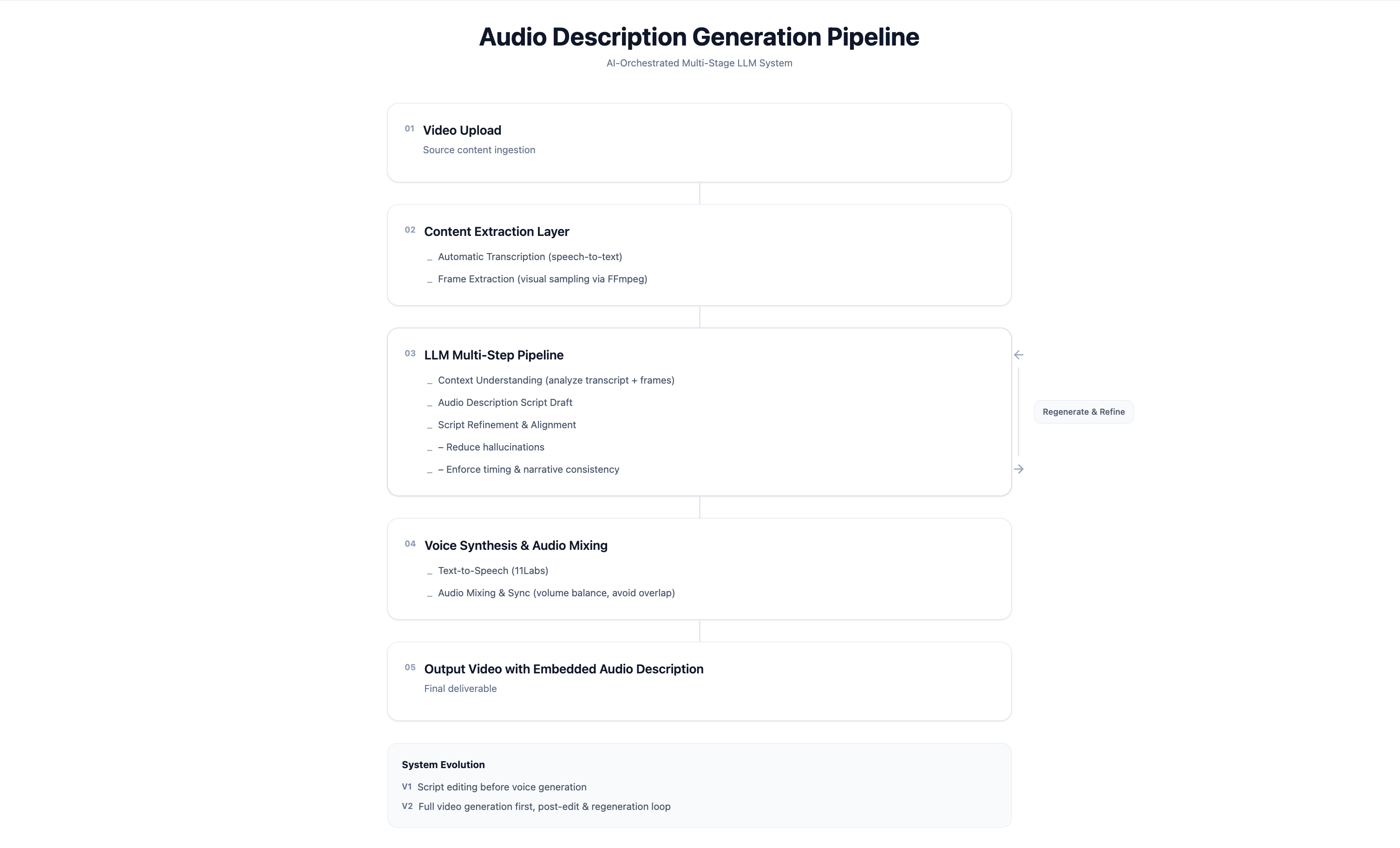
The full pipeline I designed: from video upload through LLM orchestration to final audio-described output
Automate first. Give control when needed, not the other way around.
The Key Decision
Users can't judge AI output they haven't experienced.
Version 1 asked users to edit the AI script before hearing it. In testing, nobody could judge script quality without audio context. Version 2 flipped the model: deliver the complete audio-described video first, then expose the script for optional editing.
V1: Script First
Users had to review before output. Script quality was impossible to judge without audio context.
- Generate script
- Review & edit
- Generate voice
- Embed
V2: Automation First
Output first. Script exposed for transparency. Regeneration if needed.
- Generate full audio-described video
- Expose script for transparency
- Allow regeneration if needed
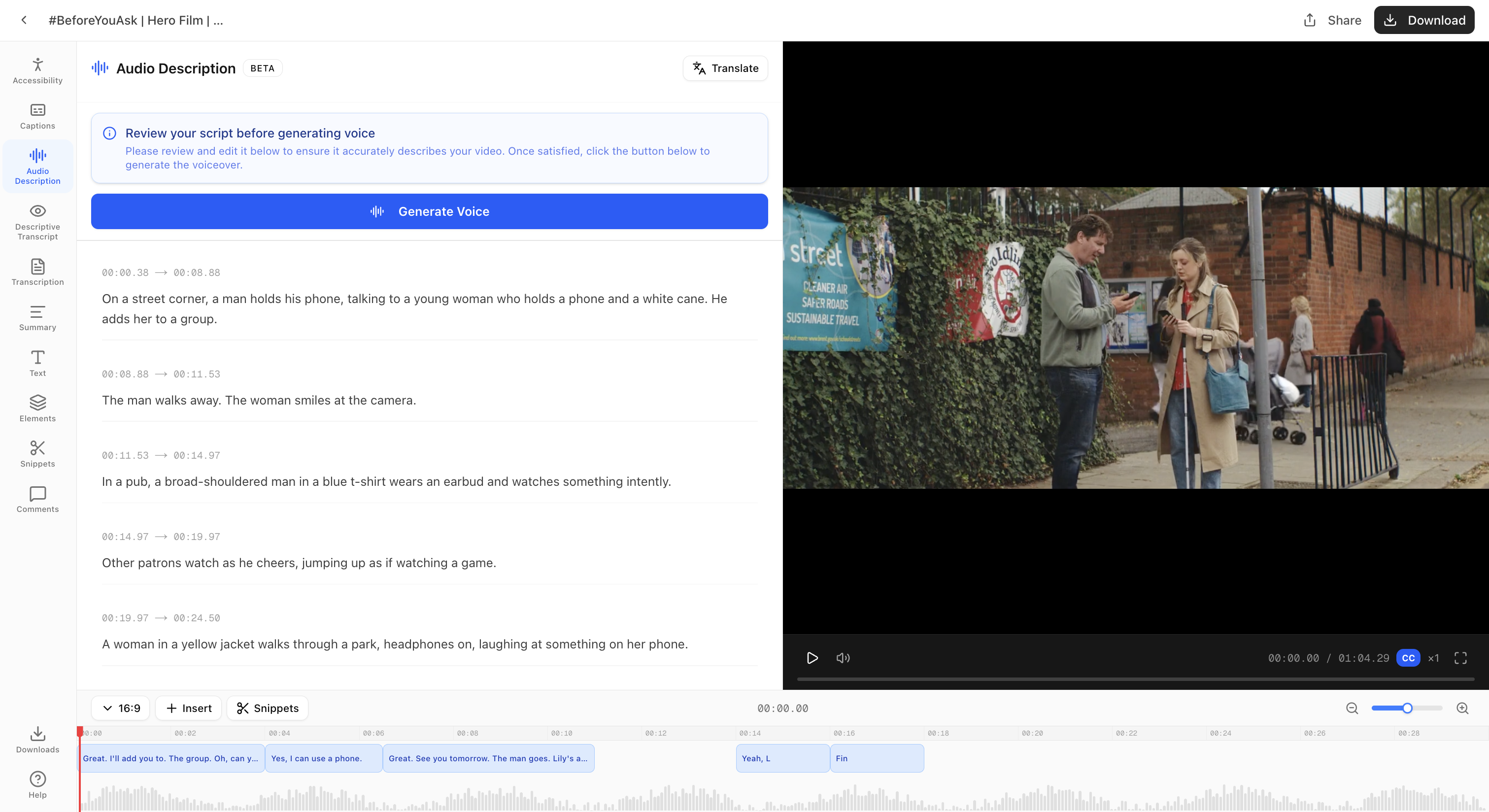
V1: Script-first. Users had to review and edit the AI script before hearing any output
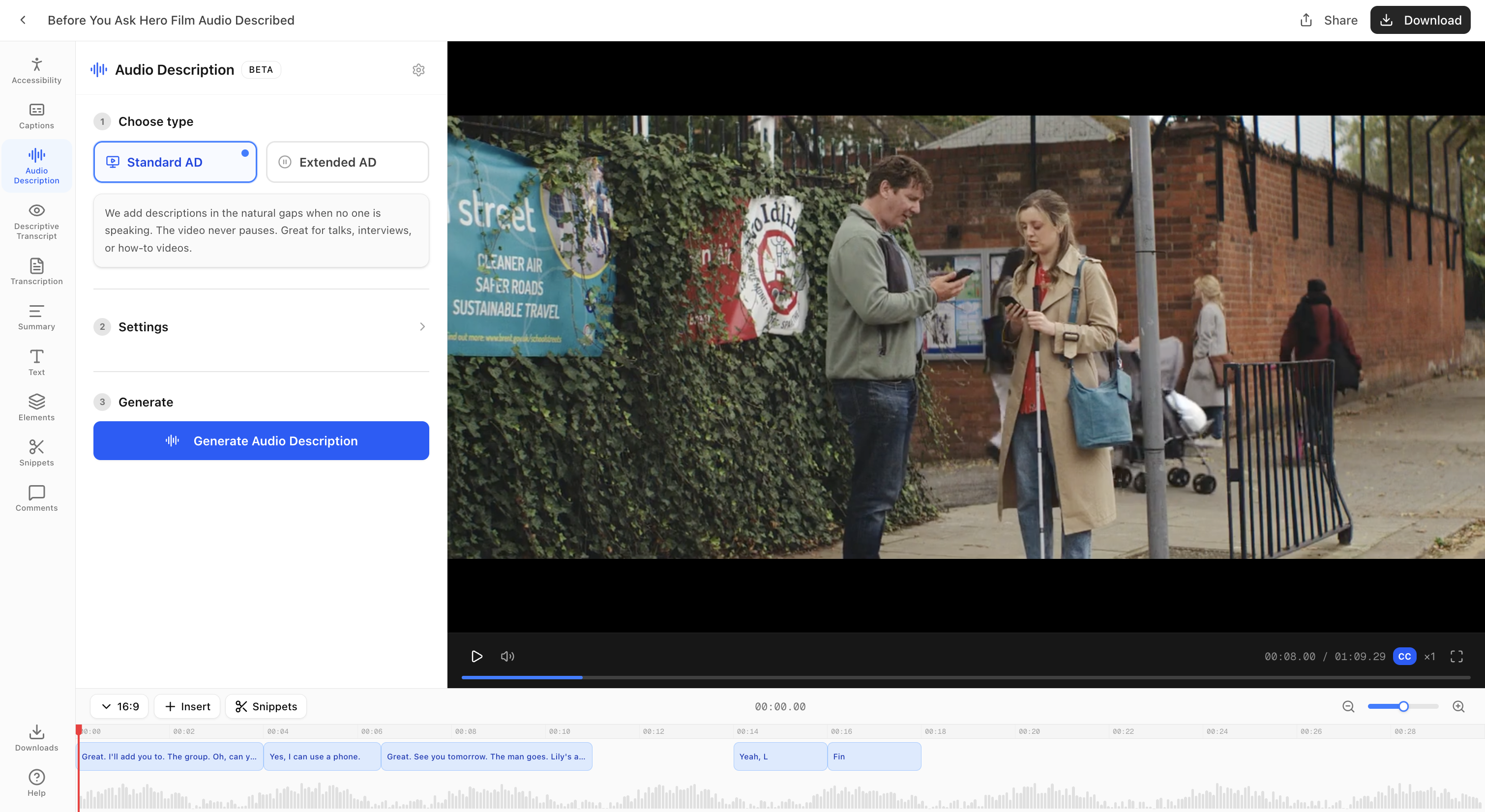
V2: Automation-first. Choose AD type, add optional context, and generate in one click
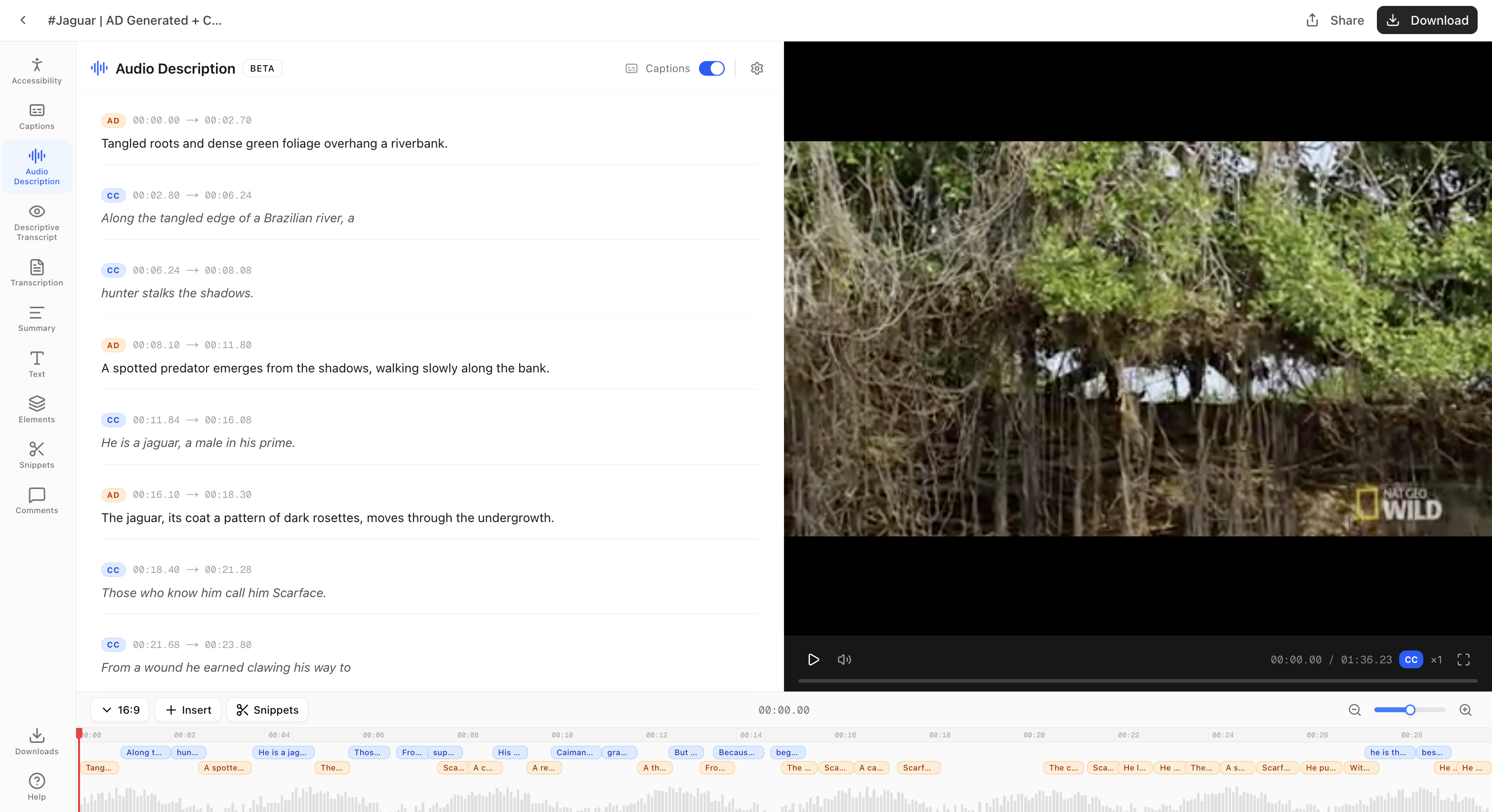
V2 output: Audio Descriptions (orange) and Captions (blue) generated and interleaved on the timeline. Full video ready to download
Script Quality
Same video. Completely different output.
The three-stage prompt architecture didn't just add more descriptions. It produced richer language, better timing coverage, and descriptions that match what's actually on screen.
AI Pipeline
Not a feature. An orchestration layer.
Audio description wasn't built as a standalone product. I designed it as an orchestration layer on top of Subly's existing transcription infrastructure. Four stages from video upload to final output.
Prompt Engineering
I designed the prompts. Not just the interface.
As sole designer, I owned the entire prompt architecture behind the audio description pipeline. This wasn't prompt tweaking. It was structural design that directly shaped output quality and reliability.
The first iteration used a two-step approach that hallucinated heavily. The AI described objects and actions that weren't in the video. Restructuring into three stages with explicit guardrails at each step reduced hallucinations significantly, making output reliable enough for enterprise accessibility compliance.
What I Learned